오늘은 논문 Quantization Friendly MobileNet(QF-MobileNet) Architecture for Vision Based Applications on Embedded Platforms 논문을 리뷰하겠습니다.
Reference
[1] 원 논문
[2] 참고 논문
Problem statement
MobileNet은 모바일, 엣지 디바이스를 위해 설계된 모델로 on-device 머신러닝에 사용될 수 있는 효율적인 CNN 모델입니다.
V1, V2, V3(small/large)로 꾸준히 성능이 개선되고있으며 다양한 임베디드 플랫폼 기반 서비스에서 사용되고 있습니다.
다만 Post Training Quantization(PTQ)를 적용하면 모델의 추론 정확도가 매우 낮아지는 문제가 있습니다.

논문은 QF-Friendly 아키텍처를 통해 PQT 이후 accuracy loss가 적은 MobileNet을 제시합니다.
MobileNetV2에 대해서는 baseline이 73.36%, 양자화 모델이 69.51%의 정확도를 보여 위 표가 제시하는 정확도 하락에 비해 개선된 모델임을 보여줍니다.
Degradation of MobileNet
그러면 왜 기본 MobileNet은 양자화 이후 추론 성능이 크게 떨어질까요?
MobileNet 아키텍쳐를 먼저 살펴보겠습니다.

Batch normalization
Baseline MobileNet을 보면 depthwise convolution, pointwise convolution 모두 output이 batch normalization layer을 거쳐서 나가며 depthwise convolution은 ReLU6 layer도 거쳐서 나갑니다.
layer input \( x = (x^{(1)}, ..., x^{(d)}) \) 이고 d-channel 을 갖으며 각 채널에 m개 원소가 있는 경우를 예로 보겠습니다.
Batch normalization 을 적용한 결과는 아래 수식으로 표현할 수 있습니다.
$$ y_i^k = a^{(k)}\hat{x}^{(k)} + b^{(k)} $$
$$ y_i^k = a^{(k)}\frac{x_i^{(k)}-\mu ^{(k)}}{\sqrt{\sigma^{(k)2} + \epsilon }} + b^{(k)} $$
\( \sigma^{(k)2} \)와 \( mu ^{(k)} \)는 mini batch k의 분산과 평균을 의미합니다.
\( \hat{x}^{(k)} \) 은 normalized x 를 의미합니다.
식을 간단하게 정리하면
$$ \alpha^{(k)} = a^{(k)}\frac{a^{(k)}}{\sqrt{\sigma^{(k)2} + \epsilon}} \quad and \quad \beta ^{(k)} = b^{(k)} - \frac{a^{(k)}\mu^{(k)}}{\sqrt{\sigma^{(k)2} + \epsilon}} $$
$$ y_i^{(k)} = \alpha ^{(k)}x_i^{(k)} + \beta ^{(k)} $$
연산량을 줄이기 위해, alpha는 각 channel k에서 독립적으로 계산됩니다.
하지만 양자화 과정에서 사용하는 x_min, x_max 값은 모든 채널에서의 값을 사용합니다.
따라서 전체적인 signal을 봤을 때 하나의 alpha 아웃라이어도 양자화 과정에서 큰 영향을 줄 수 있습니다.
특히 depthwise convolution 연산에서는 채널에서 zero value를 만들어낼 가능성이 높고 이는 zero variance로 이어집니다.
앞서 zero variance가 alpha값을 굉장히 큰 수로 증가시킬 수 있음을 보았고 이로 인해 양자화 과정에서 정확한 mapping을 할 수 없어 모델 성능이 하락합니다.

Activation function
MobileNetV2는 ReLU6, MobileNetV3는 Swish-ReLU를 사용하며 모두 비선형 함수입니다.
특히 ReLU6의 경우 activation value를 6으로 제한해 연산을 효율적으로 수행하며 활성화 함수의 sparsity를 감소해 좋은 결과를 만듭니다.

하지만 6이라는 early stage에 연산을 제한함이 signal distribution을 부자연스럽게 왜곡시켜 오히려 양자화에 부정적인 영향을 끼치게 됩니다.
Proposed method
앞서 설명드린 batch normalization, activation function의 문제를 해결하기 위한 구조는 아래와 같습니다.


Batch normalization을 depthwise convolution 이후 하지 않고 pointwise convolution까지 수행하고 적용해 zero variance 문제를 해결합니다.
또한 ReLU6를 사용하지 않고 ReLU를 사용합니다.
Experimental Results
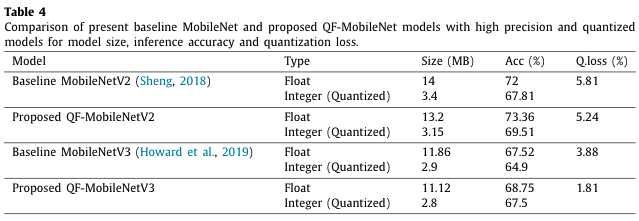
ImageNet, TensorFlow로 실험한 결과는 위 표와 같습니다.
제안한 Quantization friendly 모델의 정확도 하락이 감소함을 볼 수 있고 MobileNetV3의 경우 약 절반 정도의 하락폭으로 개선됐습니다.

Conclusion
연구가 제시한 방법을 통해 양자화에 친근한 아키텍쳐로 정확도 하락 폭을 줄였다는 좋을 결과를 얻었습니다.
제시하는 향후 연구 계획으로는 depthwise separable convolution 레이어 이외에 channel wise, layer wise quantization을 적용해 모델의 성능을 개선시킴을 제시했습니다.
'머신러닝' 카테고리의 다른 글
| [Dataset] Tiny ImageNet (0) | 2022.10.01 |
|---|---|
| [ML] MobileNetV2 with TensorFlow (0) | 2022.09.28 |
| [ML] Depthwise Separable Convolution (0) | 2022.09.16 |
| [ML] Grad-CAM Visualization (0) | 2022.09.16 |
| Raspberry Pi 4B Tensorflow 설치법 (0) | 2022.09.01 |




댓글